.svg)


Apache Druid is a solution for rapid and flexible data analysis on extensive datasets. It is especially suited for scenarios requiring real-time data ingestion, quick query responses, and high reliability.
Druid is frequently utilized as the backend database for analytical application interfaces or high-concurrency APIs that demand speedy aggregations. It is particularly effective with event-driven data.
Apache Druid's lookups are a powerful concept which gives the ability to substitute dimension values with user-predefined values at query time, without actually changing any value in Druid’s stored data.
Some common use-cases are to convert a long string to a shorter one, like saving a country-code (“US”) as a data source dimension, and replacing it with the country name (“United States of America”) only at query time. This helps reduce Druid’s storage footprint.
Another use-case is to adjust some value of historical data with a new value, without the need of ingesting the historical data all over again. For example, changing the mapping of "companyId"="123" from "Old Value" to "New Value" in the lookup will affect all of Druid’s data, no matter when ingested. Lookups also help reduce ingestion time, as there’s no need for expensive join operations while indexing data.
We at DT use Apache Druid as the core Database for our Dynamic Report, which gives all of our products' customers valuable business insights. Lookups are essential in this process, allowing us to convert internal identifiers, like application IDs, into user-friendly names for better clarity when querying the report. We’re also leveraging the fact that Druid supports polling lookup definitions via JDBC, so customers’ new configurations will be reflected immediately across all relevant data. For example, our customers might be updating their configurations using a public UI which saves these configurations in a MySQL database. When a customer updates their application name using this UI, the change will be visible in the Dynamic Report almost right away, retroactively affecting even the data that was ingested before the customer’s update.
Motivation
In the past, managing Apache Druid’s lookups was done either through Druid’s web UI or HTTP POST/DELETE request. This conventional approach led to several challenges. First, there is a lack of authentication and authorization, meaning any engineer could alter lookups. As a result, engineers less familiar with the lookups concept could unintentionally misconfigure them, causing performance degradation or data inconsistencies. For example, one might define a one-to-one lookup as non-injective, missing the opportunity to improve query time. Additionally, Druid does not keep lookups versioning history, making it impossible to roll back changes or review updates when needed. These issues highlighted the need for a more robust and structured way of managing lookups in Druid. As there is no pre-existing tool or Druid extension for such a purpose, we had to come up with an idea of our own, which we refer to as Lookups-aC or Lookups-as-Code.
Our Solution
Lookup definitions are maintained as JSON files in a Git repository, which is the configuration-repository (CR). Whenever a change is made to this repository’s main branch (via a Pull-Request merge reviewed by a data engineer) a series of Jenkins jobs get triggered via webhook (for example, by using Jenkins Generic Webhook Plugin and the webhook service of your version-control server, e.g., Gitlab Webhook). These Jenkins jobs validate the change and eventually submit it to Druid. We also enabled Druid’s Authentication mechanism so that lookup changes could be made exclusively by these Jenkins jobs.
The Benefits
Now let’s take a look at all the benefits that we get from our setup.
Versioning and History Tracking
The ability to understand why, when, and how some lookup change took place, as now the version history is well-documented as a Git graph. This allows to quickly recover in case of an inappropriate (e.g., wrong or poorly-optimized) lookup. Instead of searching “here and there” for the most (or almost) up-to-date version and then manually submitting it, Lookups-aC offers a one-click solution for restoring/rolling-back the data, as the source-control saves the most up-to-date version, and reverting a faulty lookup is as simple as reverting its corresponding Git commit. Additionally, as lookups are pre-loaded to all of Druid’s data-nodes, redundant lookups can severely impact query performance. Since lookups management is now a structured and transparent process, it is easier to avoid adding redundant lookups and to delete unnecessary ones, thus improving query performance.
No Data Entry Errors in Druid UI
Previously, an engineer was one click away from unintentionally deleting a lookup or issuing a DELETE request when intending to POST. In the worst-case scenario, this could even result in the loss of the entire lookup database. Lookups-aC significantly reduces the risk of unintended deletions which makes such incidents almost impossible.
Cross-Functional Review
With Lookups-aC, changes are made via pull requests. Once these requests are approved and merged, they are automatically reflected in Druid. This approach not only enhances security but also promotes cross-functional reviews, allowing those who best understand the required content of lookups and those who are skilled at configuring them to collaboratively maintain Druid’s lookups in the production environment. As such, performance issues will be addressed before arriving at the production environment. For example, if a lookup is not configured as “injective” whenever appropriate, this will be corrected. Business issues will also be handled, such as when the same lookup is added twice or a lookup is added with incorrect values. Another nice benefit is that now, when lookups are defined as JSON files, typo issues can be addressed before deployment. For instance, defining a lookup with a newline character in its name will be detected while it can be easily missed in the UI where such characters may go unnoticed (yes, it has happened).
Implementation
The adoption of Lookups-aC was quick. From users’ perspective not much has changed, as they still needed to write a JSON file for configuring lookups. However, instead of using Postman' or directly accessing the Druid UI, they use their preferred code editor for defining lookups. Ever since we moved to Lookups-aC, we haven't experienced any production or user-facing incidents at all!
Technical Details
Now let's dive into the technical part. Lookups-aC consists of the following components:
- Druid Configured Lookups (DCLs). The lookups definitions which Apache Druid Server actually uses when queried.
- Configuration Repository (CR). Git repository that contains each of Druid’s lookups as a JSON file. This repository is configured to trigger the following merge Jenkins job (details below) every time a pull request is being merged to the master branch.
- Jenkins jobs. Scripted Pipeline jobs, which are in charge of the interface, synchronization and consistency between the CR and DCLs.
- Merge. The main job, which consists of four stages, each one of them is simply calling another Jenkins job from the three to follow whenever appropriate.
- Validation. HTTP GET requests are sent to Druid to test whether DCLs are consistent with the lookups defined in the CR. This job is parameterized—by default it will check the master branch's latest commit but can get any other branch name or commit hash instead.
- Version-Validation. Tests whether the altered lookups also differ in their ‘Version’ key.
- Submit. Uses HTTP POST/DELETE methods to add/modify/delete lookups from DCLs, so that DCLs would be identical to those defined in the CR.
We designed it in such a modular way and not as a one big Scripted Pipeline file so that each Jenkins job could be triggered independently from the others. This helps in cases where we would like to identify issues. For example, to check whether DCL and the CR lookups are consistent using the validation job, and, if not, use the submit job to override DCL values with the CR ones.
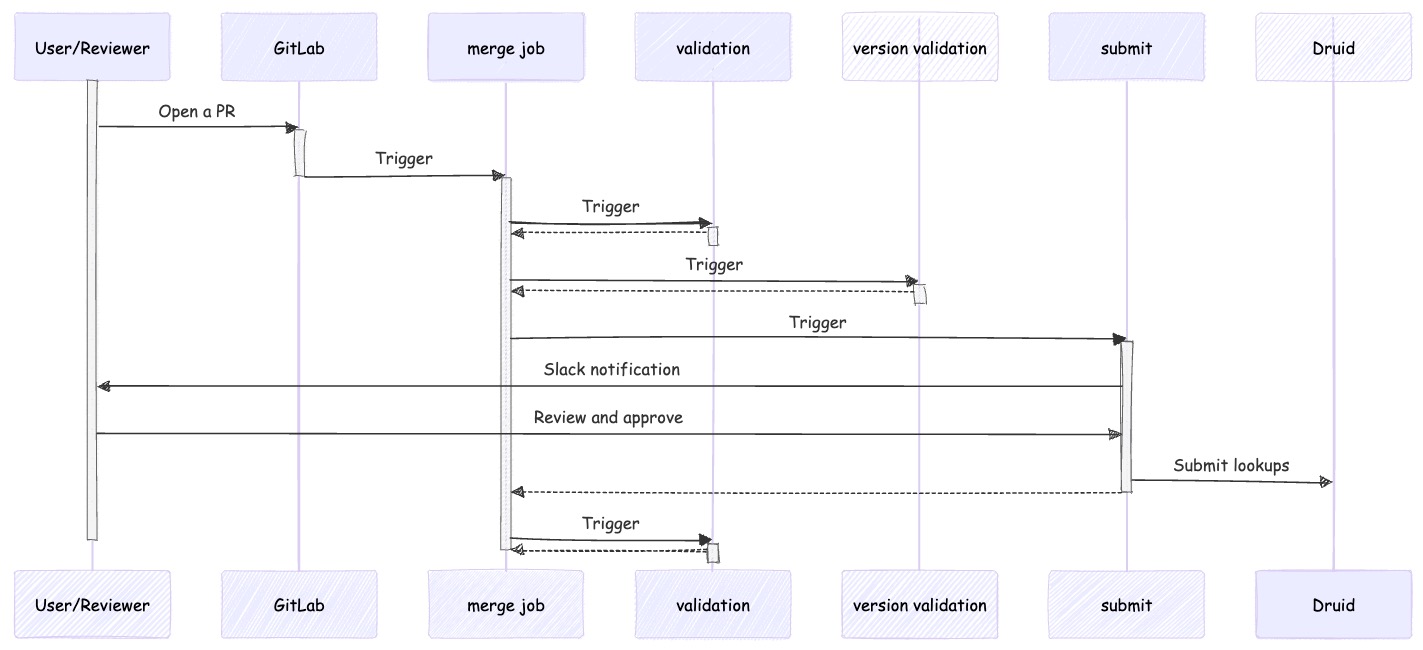
Lookup-aC In Action
Let’s see Lookups-aC in action. Suppose a user wants to add a new lookup under the default tier, mapping a country code to the country name. In order to do so, the user will define the new lookup in a side feature-branch of the CR in the __default folder. This structure tells Lookups-aC for which tier the configured lookup belongs to. We use here the default tier, but Lookups-aC will handle other tiers in the same manner.

After a pull request has been opened, approved, and merged to the CR’s master branch, the merge Jenkins job gets into action:
// File name: LookupsAcMergedPR.Jenkinsfile
stage('pre-validation') {
print "Druid's Coordinator Address: ${params.coordinator_address}"
isOldMasterAligned = checkBranchAlignment(gitlabBefore, params.coordinator_address, false) == 'SUCCESS'
isNewMasterAligned = checkBranchAlignment('*/master', params.coordinator_address, false) == 'SUCCESS'
if (!isOldMasterAligned && !isNewMasterAligned) {
error "New Master Branch is not aligned with Druid. Submitted changes won't be reflected in Druid"
} else if (!isOldMasterAligned && isNewMasterAligned) {
print "Old Master state wasn't aligned with Druid, but the current merge aligned it"
}
}
The first stage, namely pre-validation, triggers the alignment-review Jenkins job (using the checkBranchAlignment function), mainly to ensure that the CR’s master branch lookups and DCLs were consistent prior to the changes:
// File name: LookupsAcAlignmentReview.Jenkinsfile
druidTiers = lookupsAc.getDruidTiers(address).toSet()
localTiers = lookupsAc.getLocalTiers().toSet()
commonTiers = druidTiers.intersect(localTiers)
// Record tiers defined in Druid or in the Repository, but not in both
issues = getMissMatchingIssues(druidTiers, localTiers, "Tiers")
if (druidTiers != localTiers) {
print "[Warning]: Comparing Lookups only from common Tiers: " + commonTiers
}
for (tier in commonTiers) {
druidLookupsNames = lookupsAc.getDruidLookupsNames(address, tier).toSet()
localLookupsNames = lookupsAc.getLocalLookupsNames(tier).toSet()
commonLookups = druidLookupsNames.intersect(localLookupsNames)
// Record lookups defined in Druid or the Repository, but not both
issues.addAll(getMissMatchingIssues(druidLookupsNames, localLookupsNames, "Lookups"))
// Looking for definitions inconsistencies between Druid and the
// Rpoesitory among all common lookups, and record them
for (lookupName in commonLookups) {
lookupPath = "${tier}/${lookupName}"
if (!areLookupsIdentical(lookupPath, address)) {
issues.add("Druid and CaaC Repo have different versions of Lookup: ${lookupPath}")
}
}
def areLookupsIdentical(String lookupsPath, String coordinatorAddress) {
return lookupsAc.localLookup(lookupsPath) == lookupsAc.druidLookup(coordinatorAddress, lookupsPath)
}
The alignment validation logic is pretty straightforward—the pipeline records all tiers and lookups which are defined only in one of the components but not in both. Then it records all common lookups whose definitions are inconsistent between the two components, e.g., a lookup which is defined with four key-value pairs in Druid, while in the CR it has only three pairs. If there’s even one inconsistency, the job will fail, otherwise the validation job (and so the pre-validation stage) will pass:
[Pipeline] withCredentials
Masking supported pattern matches of $druid_pass or $druid_user
[Pipeline] {
[Pipeline] httpRequest
HttpMethod: GET
URL: http://druid.digitalturbine.com:8888/druid/coordinator/v1/lookups/config/__default/appIdToName
Authorization: *****
Sending request to url: http://druid.digitalturbine.com:8888/druid/coordinator/v1/lookups/config/__default/appIdToName
Response Code: HTTP/1.1 200 OK
Success: Status code 200 is in the accepted range: 200
[Pipeline] }
[Pipeline] // withCredentials
[Pipeline] readJSON
[Pipeline] readFile
[Pipeline] readJSON
[Pipeline] withCredentials
Masking supported pattern matches of $druid_pass or $druid_user
[Pipeline] {
[Pipeline] httpRequest
HttpMethod: GET
URL: http://druid.digitalturbine.com:8888/druid/coordinator/v1/lookups/config/__default/customerIdtoName
Authorization: *****
Sending request to url: http://druid.digitalturbine.com:8888/druid/coordinator/v1/lookups/config/__default/customerIdtoName
Response Code: HTTP/1.1 200 OK
Success: Status code 200 is in the accepted range: 200
[Pipeline] }
[Pipeline] // withCredentials
[Pipeline] readJSON
[Pipeline] echo
CaaC Repository and Druid Lookups are aligned
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] }
[Pipeline] // podTemplate
[Pipeline] End of Pipeline
Finished: SUCCESS
After making sure that Druid and the CR were aligned prior to the change, the ‘version-validation’ stage takes place, triggering its corresponding job that checks whether all the changed lookups in the merged commit have an upgraded version value compared to what they have in Druid. New and deleted lookups are of course being ignored.
Then, the 'submit' job gets triggered as part of the 'submit' stage. The job gathers all changes, sends a Slack notification about pending lookups changes waiting for submission, and waits for permission before proceeding. Once the permission is granted, the job finally submits these changes to Druid:
// File name: LookupsAcSubmit.Jenkinsfile
stage('Submit') {
String address = params.coordinator_address
druidTiers = lookupsAc.getDruidTiers(address).toSet()
localTiers = lookupsAc.getLocalTiers().toSet()
newTiers = localTiers - druidTiers
deletedTiers = druidTiers - localTiers
lookupsToAdd = []
lookupsToModify = []
lookupsToDelete = []
commonTiers = druidTiers.intersect(localTiers)
for (tier in commonTiers) {
druidLookupsNames = lookupsAc.getDruidLookupsNames(address, tier).toSet()
localLookupsNames = lookupsAc.getLocalLookupsNames(tier).toSet()
// New lookups which present in Repo but not in Druid
newLookups = localLookupsNames - druidLookupsNames
lookupsToAdd.addAll(getLookupPaths(tier, newLookups))
// Lookups that aren't present in Repo but do present in Druid
deletedLookups = druidLookupsNames - localLookupsNames
lookupsToDelete.addAll(getLookupPaths(tier, deletedLookups))
// Lookups that are present on both Repo and Druid, but with different Definitions
changedLookups = druidLookupsNames
.intersect(localLookupsNames)
.findAll { name -> !areLookupsIdentical(getLookupPath(tier, name), address) }
lookupsToModify.addAll(getLookupPaths(tier, changedLookups))
}
// Adding for submission all lookups from new tiers
for (tier in newTiers) {
newTierLookups = lookupsAc.getLocalLookupsNames(tier).toSet()
lookupsToAdd.addAll(getLookupPaths(tier, newTierLookups))
}
// Adding for deletion request all lookups from deleted tiers
for (tier in deletedTiers) {
deletedTierLookups = lookupsAc.getDruidLookupsNames(address, tier).toSet()
lookupsToDelete.addAll(getLookupPaths(tier, deletedTierLookups))
}
print "Lookups to Add: " + lookupsToAdd
print "Lookups to Modify: " + lookupsToModify
print "Lookups to Delete: " + lookupsToDelete
slackSend(
channel: 'team-data-ptk',
color: 'warning',
message: ":rotating_light: Druid Lookup changes are waiting for approval\n $BUILD_URL/console",
tokenCredentialId: 'slackToken'
)
input message: "-----------------------------------------------\nDo you approve the above changes?\n-----------------------------------------------\n"
print "-----------------------------------------------\nPosting new and modified Lookups to Druid\n-----------------------------------------------\n"
postDefinitions(address, lookupsToAdd + lookupsToModify)
print "-----------------------------------------------\nDeleting Lookups approved for deletion from Druid\n-----------------------------------------------\n"
deleteDefinitions(address, lookupsToDelete)
}
def getLookupPaths(String tier, HashSet lookupsNames) {
return lookupsNames.collect { lookupName -> "${tier}/${lookupName}" }
}
def postDefinitions(String coordinatorAddress, List lookupPathsToPost) {
for (lookupPath in lookupPathsToPost) {
response = lookupsAc.postDefinition(coordinatorAddress, lookupPath)
print "[SUBMIT] lookup: ${lookupPath} Submitted to Druid with Status Code: ${response.status}"
}
}
def deleteDefinitions(String coordinatorAddress, List lookupPathsToDelete) {
for (lookupPath in lookupPathsToDelete) {
response = lookupsAc.deleteDefinition(coordinatorAddress, lookupPath)
print "[DELETE] lookup: ${lookupPath} Deleted from Druid with Status Code: ${response.status}"
}
}
def areLookupsIdentical(String lookupsPath, String coordinatorAddress) {
return lookupsAc.localLookup(lookupsPath) == lookupsAc.druidLookup(coordinatorAddress, lookupsPath)
}
Here’s the 'submit' Jenkins job output:
Lookups to Add: [__default/freshLookup]
[Pipeline] echo
Lookups to Modify: []
[Pipeline] echo
Lookups to Delete: []
[Pipeline] slackSend
Slack Send Pipeline step running, values are - baseUrl: <empty>, teamDomain: digitalturbine, channel: *****, color: warning, botUser: false, tokenCredentialId: slackToken, notifyCommitters: false, iconEmoji: <empty>, username: <empty>, timestamp: <empty>
[Pipeline] input
-----------------------------------------------
Do you approve the above changes?
-----------------------------------------------
Proceed or Abort
Approved by RegevRatzon
[Pipeline] echo
-----------------------------------------------
Posting new and modified Lookups to Druid
-----------------------------------------------
[Pipeline] withCredentials
Masking supported pattern matches of $druid_pass or $druid_user
[Pipeline] {
[Pipeline] readFile
[Pipeline] httpRequest
HttpMethod: POST
URL: http://druid.digitalturbine.com:8888/druid/coordinator/v1/lookups/config/__default/freshLookup
Authorization: *****
Sending request to url: http://druid.digitalturbine.com:8888/druid/coordinator/v1/lookups/config/__default/freshLookup
Response Code: HTTP/1.1 202 Accepted
Success: Status code 202 is in the accepted range: 200,202
[Pipeline] }
[Pipeline] // withCredentials
[Pipeline] echo
[SUBMIT] lookup: __default/freshLookup Submitted to Druid with Status Code: 202
[Pipeline] echo
-----------------------------------------------
Deleting Lookups approved for deletion from Druid
-----------------------------------------------
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] }
[Pipeline] // podTemplate
[Pipeline] End of Pipeline
Finished: SUCCESS
The last stage is the post-validation, which triggers the alignment-review job once again to give a final guarantee that Druid and the CR are both aligned.
Once all of the above jobs finish successfully, the merge job, which is actually the main pipeline, finishes as well:
[Pipeline] build
Scheduling project: Data » Lookups-aC » alignment-review
Starting building: Data » Lookups-aC » alignment-review #19
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (version-validation)
[Pipeline] build
Scheduling project: Data » Lookups-aC » version-validation
Starting building: Data » Lookups-aC » version-validation #7
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (submit)
[Pipeline] build
Scheduling project: Data » Lookups-aC » submit
Starting building: Data » Lookups-aC » submit #6
[Pipeline] echo
Successfully Submitted the new Lookups definitions to Druid.
[Pipeline] }
[Pipeline] // stage
[Pipeline] stage
[Pipeline] { (post-validation)
[Pipeline] build
Scheduling project: Data » Lookups-aC » alignment-review
Starting building: Data » Lookups-aC » alignment-review #20
[Pipeline] echo
Master and Druid have been successfully aligned
[Pipeline] }
[Pipeline] // stage
[Pipeline] }
[Pipeline] // node
[Pipeline] }
[Pipeline] // podTemplate
[Pipeline] End of Pipeline
Finished: SUCCESS
Finally the new lookup change is live and can be queried:

Moving Forward
There are some improvements which we’re planning for the future. First, we think about generalizing the project so it won’t be tied up to Jenkins. We haven't thought about the exact implementation details yet, but it's definitely a goal we would like to achieve.
Another generalization we considered was to manage some other Druid components as part of Lookup-aC, as the main mechanism is the same. Some examples are Datasources retention-rules and the dynamic-configurations of the Overlord and the Coordinator.


.webp)
.jpg)


